Does AI Erode Legal Reasoning? A UMN Law Study Finds That It Did Not For Certain Tasks, With Advice on Specific Use
I provided feedback on an earlier draft of this article and am thanked in the introduction. I will aim to be fair and candid.
I provided feedback on an earlier draft of this article and am thanked in the introduction. I will aim to be fair and candid.
The main concern of the paper (and what I gather to be a focus area for years to come) is the cognitive impact of using generative AI for legal tasks. This requires both short-term and long-term studies; the authors are careful to note that negative effects may appear in longer term use of AI, but that in this particular study, the group that used AI throughout outperformed the group that only had access at the end.
This particular study is a short-term, randomized controlled trial (RCT), such as you might see more frequently in medicine (indeed, one author speculated that the use of that term may have caused public access issues for the article initially on X/Twitter).
I did not personally know Daniel Schwarcz, one of the University of Minnesota Law Professors, prior to reaching out to provide feedback on this study. But I knew of him and have a high opinion of his earlier work on cybersecurity and law. For example, Schwarcz had co-authored an excellent paper, “How Privilege Undermines Cybersecurity,” published in the Harvard Journal of Law & Technology in Spring 2023, which my group in the Dept. of Homeland Security’s Public-Private Analytic Exchange Program (AEP) read and cited in our work on Ransomware Attacks on Critical Infrastructure.
Study Design
University of Minnesota Law School professors Nick Bednar, David Cleveland, Allan Erbsen, and Daniel Schwarcz ran a randomized controlled trial involving approximately 100 2L and 3L students. The study was published April 5, 2026 on SSRN: Artificial Intelligence and Human Legal Reasoning. Strictly speaking, the comparison was not an “AI v. Not AI” group as much as an “AI from the outset” group v. an “AI as a final editor only” group.
This experiment used Google’s Gemini 2.5 Pro; I will discuss this specifically in a later section; this experiment is relevant, even for attorneys not using Gemini directly, because Gemini is the LLM behind Google AI Overviews and it is a popular API model in legal AI tools (e.g., Westlaw’s CoCounsel based on references to “Thomson Reuters AI third-party partners, such as OpenAI and Google…”).
Participants completed four sequential tasks:
- Synthesis Task (AI for AI group):
The synthesis task was designed to test whether using AI can help lawyers synthesize legal sources addressing unfamiliar subjects. We cast each participant in the role of a law firm associate who received an email from a partner asking them to summarize a legal rule based exclusively on five supplied sources. The partner explained that: “Your memo should outline the elements of the rule and any exceptions, providing a framework for how a court would approach the legal question. In other words, don’t merely summarize the sources; synthesize them into a summary of the rule that indicates how the elements fit together.”60 Participants had up to 75 minutes to read the packet and complete the memo.61 The control group was instructed not to use AI for this task, while the AI-exposed group was instructed to use Gemini 2.5 Pro62 “to assist you in writing the assignment.”
- Comprehension Task (closed book, no AI for either group): six moderately difficult multiple choice questions in ten minutes without access to either the source packet or AI.
- Application Task (access to their prior synthesis memo, no AI for either group):
That task presented participants with a follow-up email from the partner who had assigned them the synthesis task instructing them to write a memo applying their knowledge from the synthesis task to a new set of facts……“identify strengths and weaknesses in the client’s position, recommend arguments that the client should make, and rebut counterarguments.” Participants had up to 60 minutes to complete the memo.
- Revision memo (access to prior application memo, AI for both groups): revise the second memo with Gemini in 20 minutes.
Specifically, “[e]ach task related to a problem involving servitudes that burden personal property.”
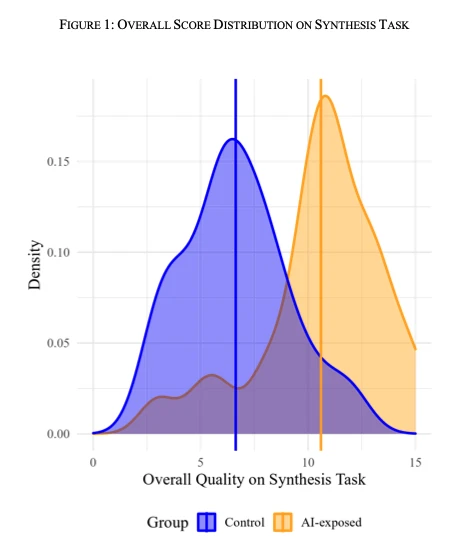
What They Found
AI helped on the synthesis task: as expected, students who used AI produced better memos and finished faster on the initial task when they had access to AI.
Early AI use did not diminish comprehension
contrary to our preregistered hypothesis, AI exposure at this initial stage did not diminish downstream comprehension of the underlying legal principles. To the contrary, participants who used AI on the synthesis task outperformed the control group on the later application task even when neither group had access to AI.
The full AI group outperformed the control (AI at the end) group. But the authors note that with long-term use, skills may atrophy. They warn that everyone (especially new lawyers) may lose or fail to develop skills if they don't learn
"to sit with a hard question, to trace an argument through its premises, to recognize when doctrine is uncertain and when it is settled" and learn to explain that reasoning to clients and to judges and lawyers, rather than delegating to AI.
"Leveling effect": AI use by high-performing individuals may degrade work product, while improving the work of the lowest performer. It didn't change the overall ranking, but made people more average. The experiment involved new information, not areas of expertise; however, the authors’ advice was to typically use AI where you are able to check the work because of your expertise.
What This Means and Connection to My CLE Advice
Like the authors, I was surprised by the results. However, the way the AI was used generally fits with the advice I give in my CLE on how to use AI responsibly.
My individual on-demand CLE courses have been approved for credit in the following states:
- Iowa: Generative Artificial Intelligence Risks and Uses for Law Firms (Activity ID #437570) and AI Gone Wrong in the Midwest (Ethics) (Activity ID #437573) — 1 hour general and 1 hour ethics.
- Illinois: Generative Artificial Intelligence Risks and Uses for Law Firms and AI Gone Wrong in the Midwest (Ethics) — AI Gone Wrong in the Midwest also received approval for Professional Responsibility credit.
- Minnesota: Generative Artificial Intelligence Risks and Uses for Law Firms and AI Gone Wrong in the Midwest (Ethics) — 1 hour general and 1 hour ethics.
- Virginia: Generative Artificial Intelligence Risks and Uses for Law Firms and AI Gone Wrong in the Midwest (Ethics) — 1 hour general and 1 hour ethics.
- Kansas: Generative Artificial Intelligence Risks and Uses for Law Firms and AI Gone Wrong in the Midwest (Ethics) — 1 hour general and 1 hour ethics.
- Nebraska: Generative Artificial Intelligence Risks and Uses for Law Firms and AI Gone Wrong in the Midwest (Ethics) — 1 hour general and 1 hour ethics (called "Professional Responsibility" in Nebraska).
- North Carolina: Generative Artificial Intelligence Risks and Uses for Law Firms and AI Gone Wrong in the Midwest (Ethics) — Generative Artificial Intelligence Risks and Uses for Law Firms is approved for Technology credit; AI Gone Wrong in the Midwest is approved for Ethics credit.
This block updates automatically as the list of CLE accreditation states changes.
Summarization as Triage, Not Replacement for Reading
In my CLE “Generative Artificial Intelligence Risks and Uses for Law Firms,” I note that you can use AI to summarize documents for triage when you have limited time. The students in the synthesis scenario only had 75 minutes to read and synthesize 5 documents.
However, I also warn that reading an AI’s summary of a document is not the same as having read the document, especially due to hallucinations. Hallucinations are not limited to making up fake case citations; they may also include fake quotations and improper summarization of the holdings of cases, for example.
Experts Should Check AI Output
I note throughout my CLE and the public talks that I give, such as my recent talk with ACAMS DC—you can watch a recording here, that the person most familiar with material should check the AI output.
For reports, this means if AI is used to write an executive summary, it should be a draft executive summary that is then reviewed and edited by the original author of the longer piece. It should not be a summary generated by a lazy reader who can’t be bothered to read the full document. The former can root out hallucinations and distortions of the writer’s intent. However, I would warn that even this use could shape the writer’s focus by making them highlight parts of the paper other than what they would have chosen had they written the executive summary from scratch.
Experts should check the output. AI can be very wordy and very persuasive. It can write things that appear to be correct. The user should not be learning something new when they are reviewing AI output, because the AI may persuade them. I warn in my CLE that sometimes AI is so persuasive, its confident hallucinations may even cause you to second-guess yourself about something you know well.
Warning About “Writing Help” at the End and Don’t Grab AI as a Last Resort
The authors recommend:
“A final principle suggested by our experimental results is that lawyers should avoid using AI to complete legal tasks under artificially tight time constraints or when cognitively fatigued.”
I frequently note that attorneys should learn about generative AI risks and responsible use now, even if they do not currently use it. Don’t wait until you feel like time pressure is forcing you to bail yourself out with AI:
- Did not go well for an attorney in Colorado who used AI and blamed it on an intern in 2023; result: temporary suspension.
- Did not go well for attorneys in New York in 2023 or an attorney in Iowa in 2025 who used AI in lieu of access to paid legal databases; result: monetary sanctions.
- Did not go well for an AUSA with a 30-year career in North Carolina who reportedly used AI to “catch up” on a filing in 2026; result: resigned from office.
Empirically, the study found that using AI at the end under tight time pressure led “in many cases [to] a modest deterioration.” I warn that even using AI just for “writing help” at the end of a task can be risky in my CLE courses, especially in “AI Gone Wrong in the Midwest.” This has caused problems for attorneys and experts witnesses. You can play an interactive demonstration of that risk and read more about it in The AI "Writing Help" Trap.
Gemini and Outdated Models in Academic Studies
This study used Gemini 2.5 Pro, but a more current Gemini model since late Fall 2025 was Gemini 3 Pro, and now there is Gemini 3.1 Pro (preview). All formal academic research seems to suffer from the problem of referencing outdated GenAI models by the time of publication.
This is not the fault of the researchers. The pace of academic publishing is simply too slow for the pace of release of major model updates. I am not the first to point this problem out, and others, e.g., Ethan Mollick, have commented on it frequently.
The most important reason I mention this is that people will cite a paper claiming “AI fails at X task” and cite a recently published academic paper, but the paper itself almost certainly doesn’t have recent models. If you look closely, it might mention “o3” or “Claude Sonnet 4” or “Gemini 2.5,” which does not invalidate the study. However, it may be demonstrably false that “AI can’t do X” today with a frontier model, if you simple logged in and tried it for yourself. Lesson: do not rely on academic studies alone for claims about the limits of what AI can do.
For this reason, I think there is a lot more value in studies like the UMN study looking at AI-human interaction. They teach us how AI works in practice and how human users respond to AI use.
Context Window
Gemini was the first major LLM to have an extremely long context window: one million tokens.1 Gemini’s long context window has made it popular for processing large numbers of documents, which might make it seem well-suited for legal purposes.
Where Gemini Has Performed Well
In addition, Gemini is a very capable model in some tests, although it fails on others. For example, Gemini has been the model most capable of identifying coded allusions to sovereign citizen legal ideology among the models I've tested.2 It also currently has the best image editing model in my opinion, and Google has SynthID for provenance verification.3
Gemini 3 was also the first LLM to pass one of my personal benchmarks.4
Where Gemini Has Performed Poorly
However, Gemini also powers the Google AI Overview and Google AI Mode, which have access to Google Search results. Despite access to the best search engine in the world, the LLM-generated summaries can still hallucinate false descriptions of nonexistent cases based on nothing but the bare case citation. Even ungrounded false information that contradicts the Google Search results with the correct answer, e.g., an OSC chastising an attorney for citing the nonexistent case. This Doppelgänger Hallucination problem has not gone away with Gemini 3.
On an AI research task in the Gemini app, Gemini 2.5 performed worse than ChatGPT. When I ran the test again, Gemini 3 still failed the test, and tried to persuade me that it had provided a comprehensive answer. I have been warning consistently that AI models are not just “getting better,” but rather they are getting “more capable.” One way this manifests itself is in LLMs becoming more persuasive about covering for their own faults.
Even when Gemini performs well, its performance can be “jagged”: impressive on one detail, hallucinating on the next in the same task.5
Bad Data Training Policy
However, I would warn attorneys to carefully consider what they put into the consumer version of Gemini if using it for work purposes, such as the non-public discussion of client position and possible strategy described in the Application Task in this experiment. Google’s Gemini has one of the worst data training opt-outs for major U.S. labs if you are using the consumer version.
Conclusion
I always try to keep up with the latest LLM research, so that I am offering fresh and accurate advice to my clients. That being said, I am also not chasing the latest fad and trend. I focus on core principles around accuracy, end-to-end processes, and realistic understanding of how human users actually relate to their AI tools. That’s why I really like this study design and encourage the authors to continue in projects like this. It is also why I stand by the advice I provided in my CLE, despite this field of GenAI changing so dramatically every couple months.
How Midwest Frontier AI Consulting Can Help
That reading informs the governance advice I give to law firms: if you'd like to put it to work for yours, schedule an introductory call.
You can take my CLE on demand on CLE Hero. Find out more details here.
Footnotes
-
Tokens are words, parts of words, or even single characters: the unit LLMs use when processing text. One million tokens in English is roughly 750,000 words, longer than War and Peace. ↩
-
I first encountered this issue when writing about the case Thomas v. Pangburn (S.D. Georgia) but have found additional examples for subsequent tests, which I have not written about publicly. ↩
-
I will be writing about SynthID more in a forthcoming series. ↩
-
Specifically, a test involving an obscure Moroccan Arabic word. I discuss the utility of personal, non-public benchmarks in my CLE. ↩
-
When fact-checking a U.S. federal court district map, Gemini correctly flagged the oft-overlooked inclusion of Yellowstone National Park in the District of Wyoming and Tenth Circuit (rather than the adjacent Montana/Idaho districts in the Ninth). That subtle catch was impressive, but in the same response it hallucinated a second "error" that was clearly not an error. ↩