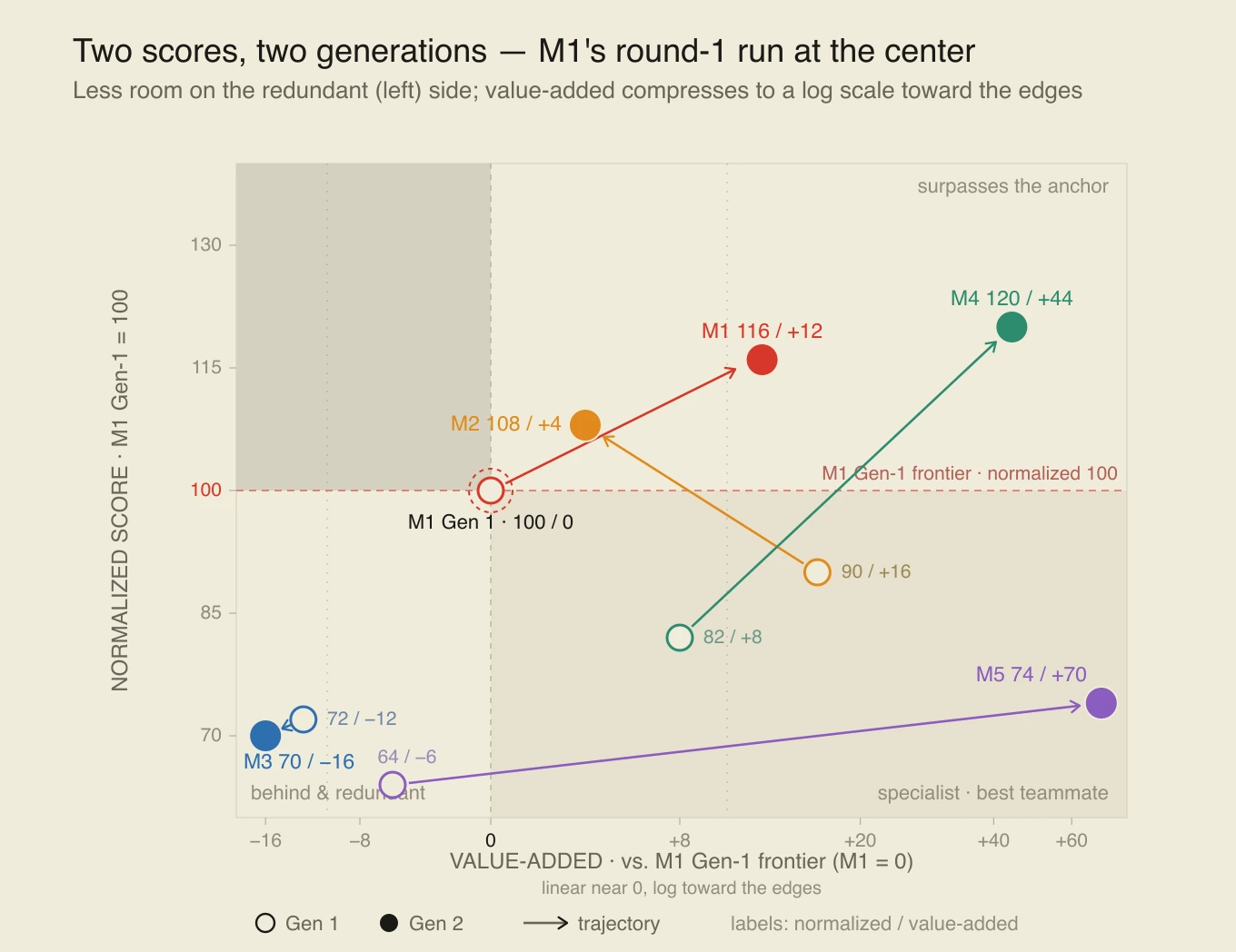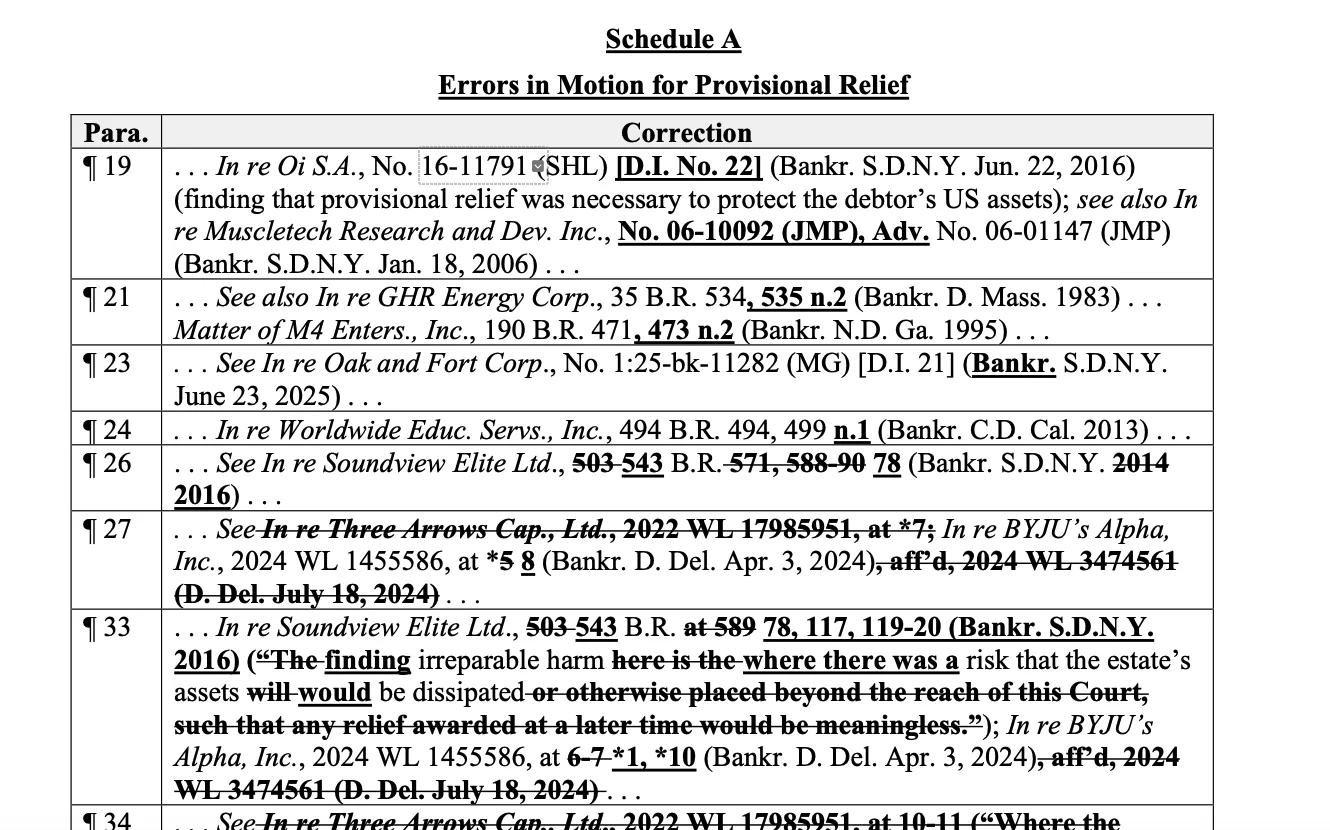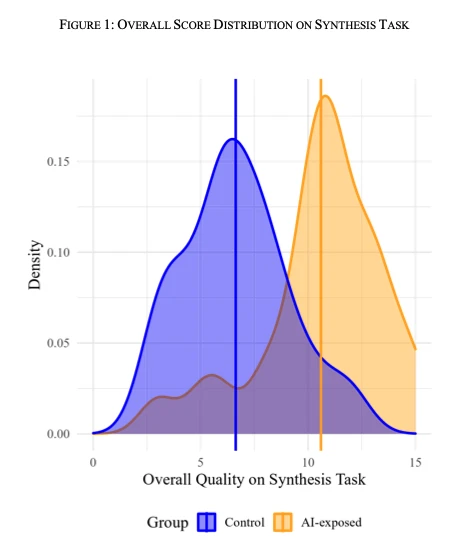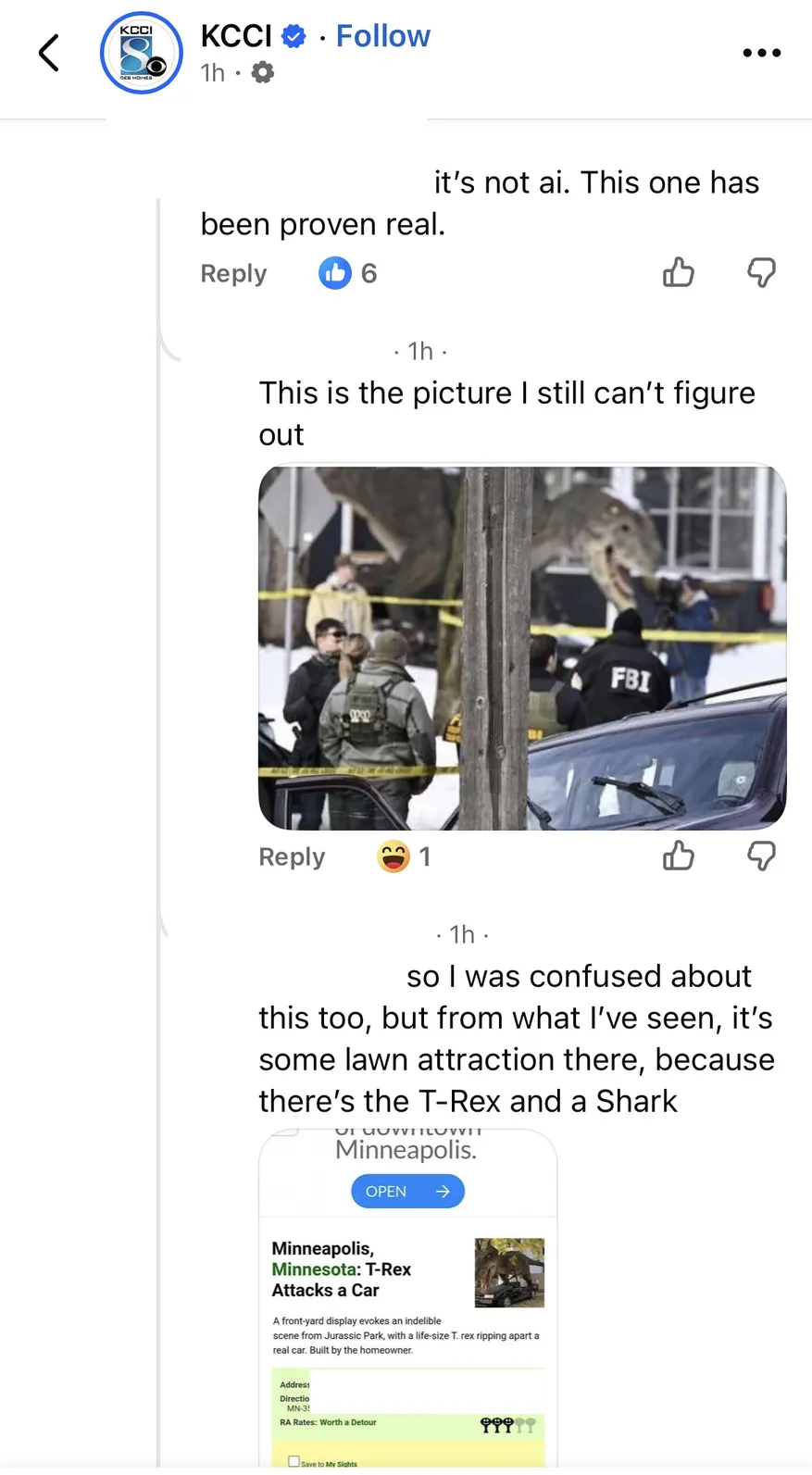
It’s Not Just GIGO: Don’t Dunk on the Dakotas and the Data Was Not the Problem
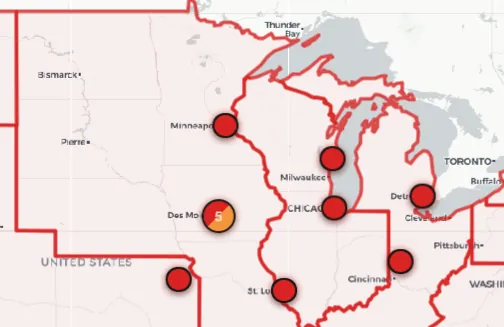
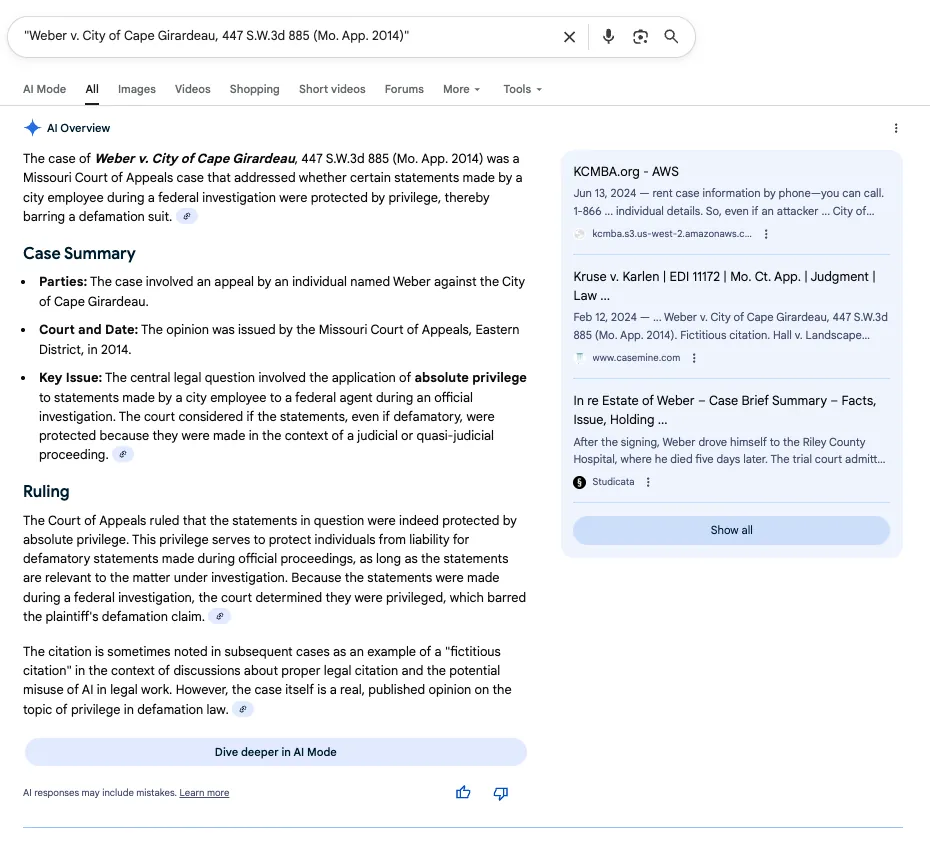
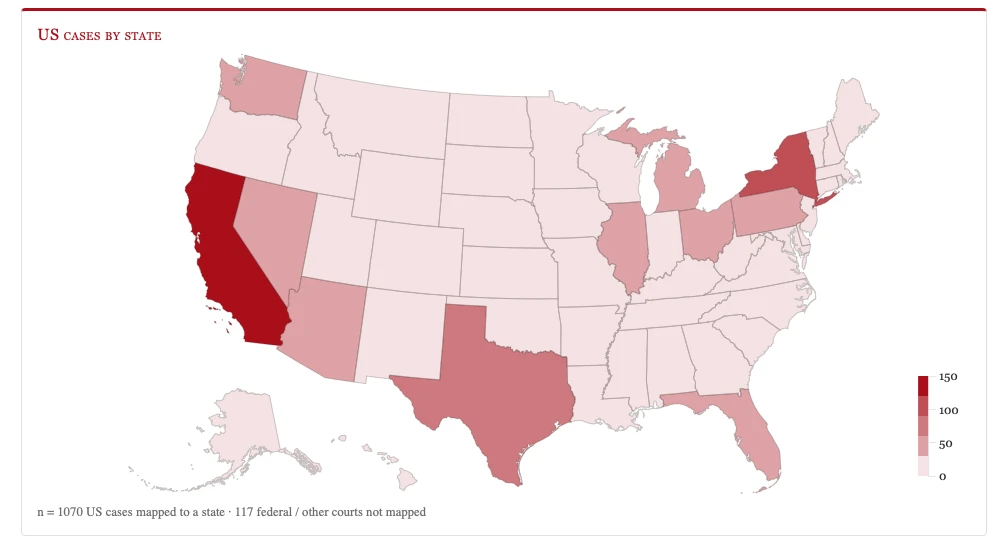
A study by an AI company claimed that ‘AI Errors’ were concentrated in North Dakota and South Dakota. The analysis was wrong, but this was not ‘garbage in, garbage out.’ While the report was supposedly analyzing Damien Charlotin’s database, the errors were not based on correctly reading the data. While looking at the underlying data, I noted additional abbreviations that may trip up LLMs and readers. In this post, I also discuss the challenges of LLMs guessing incorrectly in ambiguous situations, ungrounded hallucinations, and the fun of digging into specific data.
Chad Ratashak